正規表現に関して詳しい解説書
正規表現では扱い難い処理(HTMLの要素の抽出、Cのコメントの削除など) 06/07/19修正
正規表現と漢字
正規表現とUNIX
regexのPerl拡張の特別な挙動(1.8までのRubyの特別な挙動)
処理速度が極端に遅い、フリーズする、異常終了する(アプリケーションが固まったと思ったら)
Perlの流儀とPOSIX(動作の違い、注意点)
正規表現は文脈自由法か
boostのバグ?new
ブーリアン閉包の実装 new
状態遷移図の作成方法(図面を書くツールgraphviz)
C/C++で使用可能なライブラリ(boost,onigurma)
リンク(メジャーなとこはいちいち貼りません)
caper制作日誌
正規表現に関して詳しい解説書
コ
ンパイラ―原理・技法・ツール〈1〉
表紙の絵からレッドドラゴンブックと呼ばれています。
正規表現について記述されているのは一巻の方です。
図書館で探す場合、二分冊ではなく一冊にまとまっている古い版もあります。
こちらは緑色の表紙で、ドラゴンの絵は描かれていませんが
グリーンドラゴンブックと呼ばれています。
ア
ルゴリズムの設計と解析 2
こちらにも書かれていますが、先の本の方がおすすめです。
詳
説 正規表現第2版
有名なリファレンス本らしい。話題に出るのでなんとなくリンク。
正
規表現デスクトップリファレンス
バッドノウハウのアートに生きるPerlユーザーならこういうの必要かも。
正規表現では扱い難い処理
例:HTMLの要素の抽出
汎用の正規表現エンジンで処理するよりも、HTMLを扱う専用のNFAを実装したほうが良いです(や
り方)。
WEB上にあるHTMLは、規則が緩くてまともなパースは無理なので、仕様を工夫します。
(全体の文書構造は見ないようにし、ペアは位置を検索するだけで親子関係は無視します)
※ 06/07/19 html.rb修正@タグのペアの処理のバグFIX
例:タグ単位のアクセッサを実装したRubyのクラ
ス
require '
html' #
クリックするとクラスのソース
# HTMLファイルを解析しタイトルや画像、リンクなどを検索するプログラム
html = HTMLtokens.new
Dir.glob("*.htm*").each { |name|
html.load(name)
print "タイトル =\n"
p html.between("title")
print "コメント =\n"
p html.find("!--")
print "壁紙 =\n"
p html.findattr("body", "background")
print "画像 =\n"
p html.findattr("img", "src")
print "リンク =\n"
p html.findattr("a", "href")
}
※ XHTMLに関してはそれを扱えるパー
サ(froggerXML)が
あります。
正
規表現と漢字
マニュアルを参照して、特に漢字について言及が無い場合は対応していないと見るべきです。
ほぼ完全に扱えるのはboost::regexのようなUnicode対応のものと、
onigurumaのようなマルチバイト対応を明記しているものだけです。
対応していなくても正規表現式の一部に漢字を使える場合がありますが、
「.」や[文字クラス]、*が漢字に対して正しく動作しない可能性が高いです。
このあたりは設計の問題なので、最初から対応しているかいないのかの差が大きく
後付けのパッチよりも最初から対応しているものを選ぶべきです。
正
規表現とUNIX
UNIX環境では、コマンドに日本語パッチを当てていない場合が多いので注意してください。
また、当たっていても正規表現式のプリプロセッシング(文字クラスをORで展開など)をするなど、
苦しいパッチが当たっているケースもあります。
GNU
sedなどは一時期、内部の動作に手を入れたセロー版というものがありましたが
本家のバージョンアップが続いた後はメンテナー不足なのでしょうか、プリプロセッサになりました。
パッチが当たっているのかいないのか怪しい場合、sedやawkなどの利用を避けて、
標準で漢字ライブラリを添付しているRubyを活用するというのも手です。
regexのPerl拡張の特別な挙動
rubyのメーリングリストによると、traditional-NFAとDFAの2つのエンジンを切り替えて使うため
状況によって照合の規則が異なり、奇妙な結果になるそうです。
参照(メーリングリスト過去ログ)
>これはこういうものだと考えてもらう方が良いと思います。
文中ではNFAの限界とありますが、「従来型NFAの限界」をはしょっています。
率直な感想:POSIXのほうが動作もぱっと見で正確に見えるのに。歴史のしがらみ?
処
理速度が極端に遅い、フリーズする、異常終了する
まずは使っているソフトのバージョンを疑うべきです。
そうでない場合は正規表現式の問題です。
そもそも正規表現エンジンというものは原理的に「いかなるパターンに対しても使用できる」というものではなく、
正規表現式によっては時間量あるいは空間量の爆発が発生するものです。
そういう場合には、|(or)演算子を含む長い一本の式があれば短い複数の式に置き換える、
可能なら/a(b|c)d/の形のorを/a[bc]d/と文字クラスに置き換えるなどの対策が必要です。
プログラム的な問題の場合には、lexや[シラブル分け+ハッシュ]、手書きの専用NFAなどの
代替手段を上手に併用して回避して下さい。
こういった問題は、原理からく
るので、正規表現エンジンの改良では解決できません。
ベンチマークの比較なども線形的な問題であり、指数にくる爆発には関係ありません。
強いて改良するとするならば、一致した長さを参照しない場合に
最長一致を最短一致に変えるなど仕様をいじるようなやり方でしょう。
あとは時間量がアプリケーションのフリーズに直結する問題なので
設定したコストを超えた時に例外が飛ぶなどの工夫は欲しいところです。
(例えば設計のサンプルでは状態数の増大でコストが判定できます)
Perlの流儀とPOSIX
Perl互換の照合方式とPOSIX互換の照合方式はそれぞれ、
traditional NFA と POSIX NFA と呼ばれています。
PerlやRubyは前者、boost::regexでは後者です。
traditional NFAは状態遷移図上の経路をバックトラックによって探索し、
全ての経路を探索せずとも一致があれば終了します。
よって必ずしも最長の一致を求めません。
逆に、この経路の省略のやり方により、効率を高める自由度があります。
ただし、解が複数存在しうる場合、どの解を選ぶかについては
プログラムのつくりに影響されてしまいますから、
互換性を考慮すると設計上の制約が大きくなってしまいます。
POSIX NFAはドラゴンブックの内容と同じ動作を実現するものです。
状態遷移図上の全ての経路を探索し、DFAと同様に最長の一致を求めます。
プログラムのつくりとは関係なく、一致する長さは常に最長一致になります。
そういった意味で設計の自由度が大きくなる方式です。
POSIX非互換なマッチの例
while true #
rubyのスクリプト
printf(">")
s = gets.chomp
break if s.size < 1
b = s.match(/A+|[AB]+/)
printf("(%s)\n", b[0]) if b
end
# 実行する
>AAAAAABBBBBBBBB
(AAAAAA)
>AB
(A)
>BBBBBB
(BBBBBB)
POSIXでは常に入力全体に一致するはずのテストであるが、
これは「|」の右辺式の部分をばっさり無視する場合がある。
POSIX非互換とはこういうこと。
※ 演算子の形式にもPOSIX互換という表現があるのだが、これは照合方式とはまた別の問題であることに注意
正規表現は文脈自由法か
ドラゴンブックの範疇ではマッチングエンジンがスタックオートマトンを構成しません。
言い換えればシフト/リデュースの動作がないので条件を満たしません。
boostのバグ?
スレで、boostの動作が怪しいという指摘がありました。
boost1.33および1.33.1で/\1/を使用した場合に落ちることを確認しました。
boost::wregex re(L"(.+)[#「\\1」に傍点]"); // 落ちる
注:
パターン中の\1はバックリファレンスの値を後続するパターンとして扱うもので
上の例だとXYZ[#「XYZ」に傍点]というように一致したパターンの中身の繰り返し
演算子を変えると落ちません。
boost::wregex re(L"(.+)[#「(.+)」に傍点]"); // 落ちない
\1というのは教科書で定義される正規表現(または正則表現)の範疇を逸脱するもので、
いわゆる正規表現ではなく拡張された演算子です(状態遷移図で表現できません)。
こういった部分はプログラム的にトリッキーでバグがあってもしょうがないのではないかと思います。
状態遷移図の作成方法
図法はこちら。ツールは以下のものがおすすめです。
graphviz
使用例
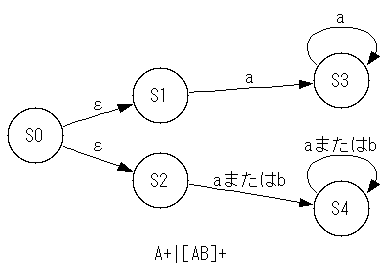
digraph "G" {
graph [fontname = "MSGOTHIC.TTC", rankdir = LR, label =
"A+|[AB]+"];
node [fontname="MSGOTHIC.TTC", shape="circle"];
edge [fontname="MSGOTHIC.TTC"];
S0 -> S1 [label="ε"];
S0 -> S2 [label="ε"];
S1 -> S3 [label="a"];
S2 -> S4 [label="aまたはb"];
S3 -> S3 [label="a", shape="doublecircle"];
S4 -> S4 [label="aまたはb", shape="doublecircle"];
}
C/C++で使用可能なライブラリ
boost::regex(翻訳版ドキュメント)
...POSIX NFA, ワイドキャラクタ
鬼車(Visual-C++用バイナ
リ) ...traditional NFA , マルチバイト
見た目の精度ならPOSIXのboost::regex
(マッチングがより人間の感覚に近いPOSIXなので感
性に対し正確である)
スクリプト言語と同等の多機能を求めるなら鬼車
(1.8より後のRubyに組み込まれる予定)
boost::regexの使用例
boost::regexで漢字を扱うにはwchar_tが適用されるwregexの方を使用する。
この場合、正規表現式および入出力はstd::wstring。
VisualC++7の場合、atlbase.h/atlconv.hの2つを取り込めばマクロのCA2W/CW2Aで
マルチバイトおよびワイドキャラクターの双方向変換が可能になる。
#include
<stdexcept>
#include <string>
#include <iostream>
#include <boost/regex.hpp>
#include <atlbase.h>
#include <atlconv.h>
int main() { // POSIX確認用サンプル
try {
boost::wregex re(L"A+|[AB]+");
boost::wsmatch m;
std::string mbuff;
std::wstring wbuff;
for (;;) {
getline(std::cin,
mbuff);
if (mbuff.size() ==
0) break;
wbuff =
CA2W(mbuff.c_str());
if
(boost::regex_search(wbuff, m, re)) {
std::wstring match = boost::regex_replace(wbuff, re, L"$0",
boost::format_all);
std::cout
<< "matched(" << CW2A(match.c_str())
<< ")" << std::endl;
}
}
} catch (std::exception &e) {
std::cout << e.what()
<< std::endl;
exit(1);
}
exit(0);
return 0;
}
著作権に関して
基本的に公開したプログラムも書籍と同等とみなし、常識的な範囲の複製および引用は自由であると考えています。
業者レベルの視点で見ると、このようなフリーソフトを仕事で使い、それを顧客に譲渡するということは
面倒なやっかい事であり、無料であってもドキュメントに本人がハンコを押してないソースには有り難味はありません。
そういう意味で、私はプログラムの注文を受け付ける可能性があると宣言しておきます。
